publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
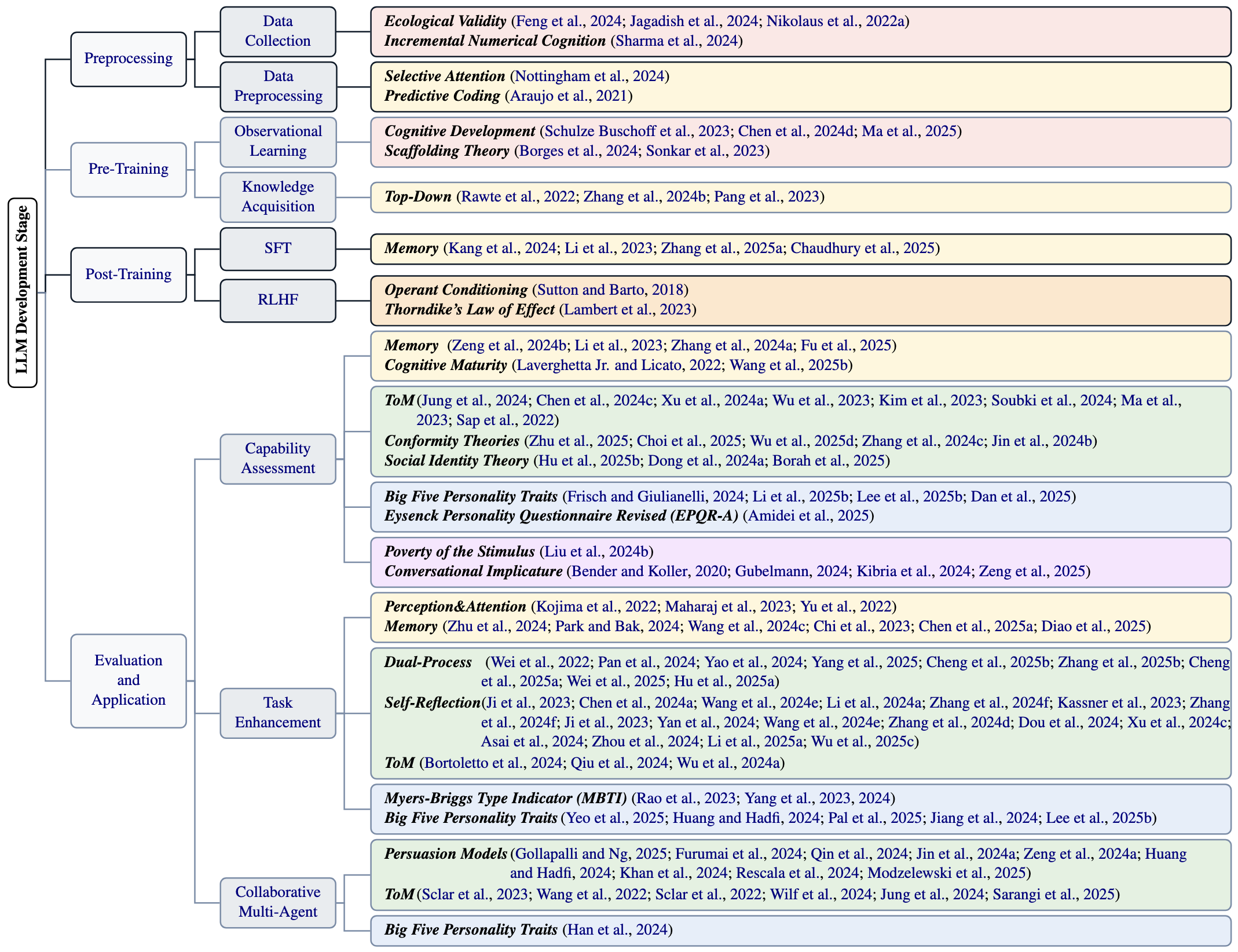 The mind in the machine: A survey of incorporating psychological theories in llmsZizhou Liu , Ziwei Gong , Lin Ai, Zheng Hui , Run Chen , Colin Wayne Leach , and 2 more authorsarXiv preprint arXiv:2505.00003, 2025
The mind in the machine: A survey of incorporating psychological theories in llmsZizhou Liu , Ziwei Gong , Lin Ai, Zheng Hui , Run Chen , Colin Wayne Leach , and 2 more authorsarXiv preprint arXiv:2505.00003, 2025Psychological insights have long shaped pivotal NLP breakthroughs, including the cognitive underpinnings of attention mechanisms, formative reinforcement learning, and Theory of Mind-inspired social modeling. As Large Language Models (LLMs) continue to grow in scale and complexity, there is a rising consensus that psychology is essential for capturing human-like cognition, behavior, and interaction. This paper reviews how psychological theories can inform and enhance stages of LLM development, including data, pre-training, post-training, and evaluation&application. Our survey integrates insights from cognitive, developmental, behavioral, social, personality psychology, and psycholinguistics. Our analysis highlights current trends and gaps in how psychological theories are applied. By examining both cross-domain connections and points of tension, we aim to bridge disciplinary divides and promote more thoughtful integration of psychology into future NLP research.
@article{liu2025mind, title = {The mind in the machine: A survey of incorporating psychological theories in llms}, author = {Liu, Zizhou and Gong, Ziwei and Ai, Lin and Hui, Zheng and Chen, Run and Leach, Colin Wayne and Greene, Michelle R and Hirschberg, Julia}, journal = {arXiv preprint arXiv:2505.00003}, year = {2025}, } - SMARTMiner: Extracting and Evaluating SMART Goals from Low-Resource Health Coaching NotesIva Bojic , Qi Chwen Ong , Stephanie Hilary Xinyi Ma , Lin Ai, Zheng Liu , Ziwei Gong , and 3 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2025, Nov 2025
We present SMARTMiner, a framework for extracting and evaluating specific, measurable, attainable, relevant, time-bound (SMART) goals from unstructured health coaching (HC) notes. Developed in response to challenges observed during a clinical trial, the SMARTMiner achieves two tasks: (i) extracting behavior change goal spans and (ii) categorizing their SMARTness. We also introduce SMARTSpan, the first publicly available dataset of 173 HC notes annotated with 266 goals and SMART attributes. SMARTMiner incorporates an extractive goal retriever with a component-wise SMARTness classifier. Experiment results show that extractive models significantly outperformed their generative counterparts in low-resource settings, and that two-stage fine-tuning substantially boosted performance. The SMARTness classifier achieved up to 0.91 SMART F1 score, while the full SMARTMiner maintained high end-to-end accuracy. This work bridges healthcare, behavioral science, and natural language processing to support health coaches and clients with structured goal tracking - paving way for automated weekly goal reviews between human-led HC sessions. Both the code and the dataset are available at: https://github.com/IvaBojic/SMARTMiner.
@inproceedings{bojic-etal-2025-smartminer, title = {{SMARTM}iner: Extracting and Evaluating {SMART} Goals from Low-Resource Health Coaching Notes}, author = {Bojic, Iva and Ong, Qi Chwen and Ma, Stephanie Hilary Xinyi and Ai, Lin and Liu, Zheng and Gong, Ziwei and Hirschberg, Julia and Ho, Andy Hau Yan and Khong, Andy W. H.}, editor = {Christodoulopoulos, Christos and Chakraborty, Tanmoy and Rose, Carolyn and Peng, Violet}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2025}, month = nov, year = {2025}, address = {Suzhou, China}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.findings-emnlp.885/}, doi = {10.18653/v1/2025.findings-emnlp.885}, pages = {16288--16305}, isbn = {979-8-89176-335-7}, } - Personalized Attacks of Social Engineering in Multi-turn Conversations–LLM Agents for Simulation and DetectionTharindu Kumarage , Cameron Johnson , Jadie Adams , Lin Ai, Matthias Kirchner , Anthony Hoogs , and 4 more authorsarXiv preprint arXiv:2503.15552, Nov 2025
The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the SE attack mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims’ personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.
@article{kumarage2025personalized, title = {Personalized Attacks of Social Engineering in Multi-turn Conversations--LLM Agents for Simulation and Detection}, author = {Kumarage, Tharindu and Johnson, Cameron and Adams, Jadie and Ai, Lin and Kirchner, Matthias and Hoogs, Anthony and Garland, Joshua and Hirschberg, Julia and Basharat, Arslan and Liu, Huan}, journal = {arXiv preprint arXiv:2503.15552}, year = {2025}, } - Learning More with Less: Self-Supervised Approaches forLow-Resource Speech Emotion RecognitionZiwei Gong , Pengyuan Shi , Kaan Donbekci , Lin Ai, Run Chen , David Sasu , and 2 more authorsIn Interspeech 2025, Nov 2025
Speech Emotion Recognition (SER) has seen significant progress with deep learning, yet remains challenging for Low-Resource Languages (LRLs) due to the scarcity of annotated data. In this work, we explore unsupervised learning to improve SER in low-resource settings. Specifically, we investigate contrastive learning (CL) and Bootstrap Your Own Latent (BYOL) as self-supervised approaches to enhance cross-lingual generalization. Our methods achieve notable F1 score improvements of 10.6% in Urdu, 15.2% in German, and 13.9% in Bangla, demonstrating their effectiveness in LRLs. Additionally, we analyze model behavior to provide insights on key factors influencing performance across languages, and also highlighting challenges in low-resource SER. This work provides a foundation for developing more inclusive, explainable, and robust emotion recognition systems for underrepresented languages.
@inproceedings{gong25b_interspeech, title = {Learning More with Less: Self-Supervised Approaches forLow-Resource Speech Emotion Recognition}, author = {Gong, Ziwei and Shi, Pengyuan and Donbekci, Kaan and Ai, Lin and Chen, Run and Sasu, David and Wu, Zehui and Hirschberg, Julia}, year = {2025}, booktitle = {Interspeech 2025}, pages = {151--155}, doi = {10.21437/Interspeech.2025-1006}, issn = {2958-1796}, } - Comparison-Based Automatic Evaluation for Meeting SummarizationZiwei Gong , Lin Ai, Harsh Deshpande , Alexander Johnson , Emmy Phung , Zehui Wu , and 2 more authorsIn Interspeech 2025, Nov 2025
Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-based Reference-free Elo-ranked Automatic evaluation for Meeting summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
@inproceedings{gong25c_interspeech, title = {Comparison-Based Automatic Evaluation for Meeting Summarization}, author = {Gong, Ziwei and Ai, Lin and Deshpande, Harsh and Johnson, Alexander and Phung, Emmy and Wu, Zehui and Emami, Ahmad and Hirschberg, Julia}, year = {2025}, booktitle = {Interspeech 2025}, pages = {291--295}, doi = {10.21437/Interspeech.2025-2771}, issn = {2958-1796}, } - Akan Cinematic Emotions (ACE): A Multimodal Multi-party Dataset for Emotion Recognition in Movie DialoguesDavid Sasu , Zehui Wu , Ziwei Gong , Run Chen , Pengyuan Shi , Lin Ai, and 2 more authorsIn Findings of the Association for Computational Linguistics: ACL 2025, Jul 2025
@inproceedings{sasu-etal-2025-akan, title = {Akan Cinematic Emotions (ACE): A Multimodal Multi-party Dataset for Emotion Recognition in Movie Dialogues}, author = {Sasu, David and Wu, Zehui and Gong, Ziwei and Chen, Run and Shi, Pengyuan and Ai, Lin and Hirschberg, Julia and Schluter, Natalie}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2025}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, } - Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal NuancesZehui Wu , Ziwei Gong , Lin Ai, Pengyuan Shi , Kaan Donbekci , and Julia HirschbergIn Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Apr 2025
This paper introduces a novel approach to emotion detection in speech using Large Language Models (LLMs). We address the limitation of LLMs in processing audio inputs by translating speech characteristics into natural language descriptions. Our method integrates these descriptions into text prompts, enabling LLMs to perform multimodal emotion analysis without architectural modifications. We evaluate our approach on two datasets: IEMOCAP and MELD, demonstrating significant improvements in emotion recognition accuracy, particularly for high-quality audio data. Our experiments show that incorporating speech descriptions yields a 2 percentage point increase in weighted F1 score on IEMOCAP (from 70.111% to 72.596%). We also compare various LLM architectures and explore the effectiveness of different feature representations. Our findings highlight the potential of this approach in enhancing emotion detection capabilities of LLMs and underscore the importance of audio quality in speech-based emotion recognition tasks. We’ll release the source code on Github.
@inproceedings{wu2024beyond, title = {Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances}, author = {Wu, Zehui and Gong, Ziwei and Ai, Lin and Shi, Pengyuan and Donbekci, Kaan and Hirschberg, Julia}, booktitle = {Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, publisher = {Association for Computational Linguistics}, month = apr, year = {2025}, address = {Albuquerque, New Mexico, USA}, } - NovAScore: A New Automated Metric for Evaluating Document Level NoveltyLin Ai, Ziwei Gong , Harshsaiprasad Deshpande , Alexander Johnson , Emmy Phung , Ahmad Emami , and 1 more authorIn Proceedings of the 31st International Conference on Computational Linguistics, Jan 2025
The rapid expansion of online content has intensified the issue of information redundancy, underscoring the need for solutions that can identify genuinely new information. Despite this challenge, the research community has seen a decline in focus on novelty detection, particularly with the rise of large language models (LLMs). Additionally, previous approaches have relied heavily on human annotation, which is time-consuming, costly, and particularly challenging when annotators must compare a target document against a vast number of historical documents. In this work, we introduce NovAScore (Novelty Evaluation in Atomicity Score), an automated metric for evaluating document-level novelty. NovAScore aggregates the novelty and salience scores of atomic information, providing high interpretability and a detailed analysis of a document’s novelty. With its dynamic weight adjustment scheme, NovAScore offers enhanced flexibility and an additional dimension to assess both the novelty level and the importance of information within a document. Our experiments show that NovAScore strongly correlates with human judgments of novelty, achieving a 0.626 Point-Biserial correlation on the TAP-DLND 1.0 dataset and a 0.920 Pearson correlation on an internal human-annotated dataset.
@inproceedings{ai-etal-2025-novascore, title = {NovAScore: A New Automated Metric for Evaluating Document Level Novelty}, author = {Ai, Lin and Gong, Ziwei and Deshpande, Harshsaiprasad and Johnson, Alexander and Phung, Emmy and Emami, Ahmad and Hirschberg, Julia}, booktitle = {Proceedings of the 31st International Conference on Computational Linguistics}, publisher = {Association for Computational Linguistics}, month = jan, year = {2025}, address = {Abu Dhabi, UAE}, } - PropaInsight: Toward Deeper Understanding of Propaganda in Terms of Techniques, Appeals, and IntentJiateng Liu* , Lin Ai * , Zizhou Liu , Payam Karisani , Zheng Hui , May Fung , and 3 more authorsIn Proceedings of the 31st International Conference on Computational Linguistics, Jan 2025
Propaganda plays a critical role in shaping public opinion and fueling disinformation. While existing research primarily focuses on identifying propaganda techniques, it lacks the ability to capture the broader motives and the impacts of such content. To address these challenges, we introduce PropaInsight, a conceptual framework grounded in foundational social science research, which systematically dissects propaganda into techniques, arousal appeals, and underlying intent. PropaInsight offers a more granular understanding of how propaganda operates across different contexts. Additionally, we present PropaGaze, a novel dataset that combines human-annotated data with high-quality synthetic data generated through a meticulously designed pipeline. Our experiments show that off-the-shelf LLMs struggle with propaganda analysis, but training with PropaGaze significantly improves performance. Fine-tuned Llama-7B-Chat achieves 203.4% higher text span IoU in technique identification and 66.2% higher BertScore in appeal analysis compared to 1-shot GPT-4-Turbo. Moreover, PropaGaze complements limited human-annotated data in data-sparse and cross-domain scenarios, showing its potential for comprehensive and generalizable propaganda analysis.
@inproceedings{liu-etal-2025-propainsight, title = {PropaInsight: Toward Deeper Understanding of Propaganda in Terms of Techniques, Appeals, and Intent}, author = {Liu, Jiateng and Ai, Lin and Liu, Zizhou and Karisani, Payam and Hui, Zheng and Fung, May and Nakov, Preslav and Hirschberg, Julia and Ji, Heng}, booktitle = {Proceedings of the 31st International Conference on Computational Linguistics}, publisher = {Association for Computational Linguistics}, month = jan, year = {2025}, address = {Abu Dhabi, UAE}, }









2024
- Enhancing Pre-Trained Generative Language Models with Question Attended Span Extraction on Machine Reading ComprehensionLin Ai, Zheng Hui , Zizhou Liu , and Julia HirschbergIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Jan 2024
Machine Reading Comprehension (MRC) poses a significant challenge in the field of Natural Language Processing (NLP). While mainstream MRC methods predominantly leverage extractive strategies using encoder-only models such as BERT, generative approaches face the issue of out-of-control generation – a critical problem where answers generated are often incorrect, irrelevant, or unfaithful to the source text. To address these limitations in generative models for MRC, we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the fine-tuning phase of pre-trained generative language models (PLMs), QASE significantly enhances their performance, allowing them to surpass the extractive capabilities of advanced Large Language Models (LLMs) such as GPT-4. Notably, these gains in performance do not come with an increase in computational demands. The efficacy of the QASE module has been rigorously tested across various datasets, consistently achieving or even surpassing state-of-the-art (SOTA) results.
@inproceedings{ai-etal-2024-enhancing, title = {Enhancing Pre-Trained Generative Language Models with Question Attended Span Extraction on Machine Reading Comprehension}, author = {Ai, Lin and Hui, Zheng and Liu, Zizhou and Hirschberg, Julia}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, } - Defending Against Social Engineering Attacks in the Age of LLMsLin Ai * , Tharindu Kumarage* , Amrita Bhattacharjee* , Zizhou Liu , Zheng Hui , Michael Davinroy , and 9 more authorsIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Jan 2024
The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
@inproceedings{ai-etal-2024-defending, title = {Defending Against Social Engineering Attacks in the Age of LLMs}, author = {Ai, Lin and Kumarage, Tharindu and Bhattacharjee, Amrita and Liu, Zizhou and Hui, Zheng and Davinroy, Michael and Cook, James and Cassani, Laura and Trapeznikov, Kirill and Kirchner, Matthias and Basharat, Arslan and Hoogs, Anthony and Garland, Joshua and Liu, Huan and Hirschberg, Julia}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, } - A Survey on Open Information Extraction from Rule-based Model to Large Language ModelPai Liu* , Wenyang Gao* , Wenjie Dong* , Lin Ai * , Ziwei Gong* , Songfang Huang , and 4 more authorsIn Findings of the Association for Computational Linguistics: EMNLP 2024, Jan 2024
Open Information Extraction (OpenIE) represents a crucial NLP task aimed at deriving structured information from unstructured text, unrestricted by relation type or domain. This survey paper provides an overview of OpenIE technologies spanning from 2007 to 2024, emphasizing a chronological perspective absent in prior surveys. It examines the evolution of task settings in OpenIE to align with the advances in recent technologies. The paper categorizes OpenIE approaches into rule-based, neural, and pre-trained large language models, discussing each within a chronological framework. Additionally, it highlights prevalent datasets and evaluation metrics currently in use. Building on this extensive review, the paper outlines potential future directions in terms of datasets, information sources, output formats, methodologies, and evaluation metrics.
@inproceedings{pai-etal-2024-survey, title = {A Survey on Open Information Extraction from Rule-based Model to Large Language Model}, author = {Liu, Pai and Gao, Wenyang and Dong, Wenjie and Ai, Lin and Gong, Ziwei and Huang, Songfang and Li, Zongsheng and Hoque, Ehsan and Hirschberg, Julia and Zhang, Yue}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, } - TweetIntent@Crisis: A Dataset Revealing Narratives of Both Sides in the Russia-Ukraine CrisisLin Ai, Sameer Gupta , Shreya Oak , Zheng Hui , Zizhou Liu , and Julia HirschbergIn Proceedings of the International AAAI Conference on Web and Social Media, Jan 2024
This paper introduces TweetIntent@Crisis, a novel Twitter dataset centered on the Russia-Ukraine crisis. Comprising over 17K tweets from government-affiliated accounts of both nations, the dataset is meticulously annotated to identify underlying intents and detailed intent-related information. Our analysis demonstrates the dataset’s capability in revealing fine-grained intents and nuanced narratives within the tweets from both parties involved in the crisis. We aim for TweetIntent@Crisis to provide the research community with a valuable tool for understanding and analyzing granular media narratives and their impact in this geopolitical conflict.
@inproceedings{ai2024tweetintent, title = {TweetIntent@Crisis: A Dataset Revealing Narratives of Both Sides in the Russia-Ukraine Crisis}, author = {Ai, Lin and Gupta, Sameer and Oak, Shreya and Hui, Zheng and Liu, Zizhou and Hirschberg, Julia}, booktitle = {Proceedings of the International AAAI Conference on Web and Social Media}, volume = {18}, pages = {1872--1887}, year = {2024}, }




2023
- Combating the COVID-19 Infodemic: Untrustworthy Tweet Classification using Heterogeneous Graph TransformerLin Ai, Zizhou Liu , and Julia HirschbergIn Workshop Proceedings of the 17th International AAAI Conference on Web and Social Media, Jan 2023
While COVID-19 has affected most of the world, attempts to control it have been difficult due to the lack of trustworthy information about the virus’s origin, severity, effective treatments, and prevention measures. To address this, we have collected RTCas-COVID-19, a large corpus of 35M COVID-19 tweets from 2020, and weak-labeled 2M with a semi-supervised approach. We have also developed an inductive framework, RTCS-HGT (Retweet Cascade Subgraph Sampling Heterogeneous Graph Transformer), which achieves 0.918 test accuracy on tweet trustworthiness classification on our dataset and improves training time by 93%.
@inproceedings{ai2022combating, title = {Combating the COVID-19 Infodemic: Untrustworthy Tweet Classification using Heterogeneous Graph Transformer}, author = {Ai, Lin and Liu, Zizhou and Hirschberg, Julia}, booktitle = {Workshop Proceedings of the 17th International AAAI Conference on Web and Social Media}, year = {2023}, } - What Makes A Video Radicalizing? Identifying Sources of Influence in QAnon VideosLin Ai, Yu-Wen Chen , Yuwen Yu , Seoyoung Kweon , Julia Hirschberg , and Sarah Ita LevitanThe 9th International Conference on Computational Social Science, Jan 2023
In recent years, radicalization is being increasingly attempted on video-sharing platforms. Previous studies have been proposed to identify online radicalization using generic social context analysis, without taking into account comprehensive viewer traits and how those can affect viewers’ perception of radicalizing content. To address the challenge, we examine QAnon, a conspiracy-based radicalizing group, and have designed a comprehensive questionnaire aiming to understand viewers’ perceptions of QAnon videos. We outline the traits of viewers that QAnon videos are the most appealing to, and identify influential factors that impact viewers’ perception of the videos.
@article{ai2024makes, title = {What Makes A Video Radicalizing? Identifying Sources of Influence in QAnon Videos}, author = {Ai, Lin and Chen, Yu-Wen and Yu, Yuwen and Kweon, Seoyoung and Hirschberg, Julia and Levitan, Sarah Ita}, journal = {The 9th International Conference on Computational Social Science}, year = {2023}, }


2021
- Identifying the Popularity and Persuasiveness of Right- and Left-Leaning Group Videos on Social MediaLin Ai, Anika Kathuria , Subhadarshi Panda , Arushi Sahai , Yuwen Yu , Sarah Ita Levitan , and 1 more authorIn 2021 IEEE international conference on big data (big data), Jan 2021
We have collected over 30,000 right- and left-leaning groups’ videos from YouTube, Bitchute, 4Chan and Vimeo to identify aspects of their content and presentation which make these videos more popular and also potentially more persuasive. To date we have collected videos for and against Antifa and other anti-Fascist groups, Black Lives Matter, Proud Boys, Oath Keepers and QAnon and manually labelled subsets for style, stance toward the group, persuasiveness, techniques used and other features. We have also extracted video features including titles, descriptions, time of upload, captions and ASR transcripts, topic categories, and users’ likes, dislikes, comments, and views. We are currently using these to automatically identify information such as the stance of the video (for or against a group), changes in popularity and in the sentiment of viewers toward the videos over time, correlating these changes with major events. We are also extracting text and audio features from videos and their comments to develop multimodal Machine Learning models for use in identifying different types of videos (e.g. pro- and anti- a group, extremely popular or unpopular) and eventually to use in identifying new radical groups and tracking their success. We will also be crowdsourcing surveys of subsets of these videos to understand how persons with different demographics and personality types perceive and are potentially influenced by different groups and different types of videos.
@inproceedings{ai2021identifying, title = {Identifying the Popularity and Persuasiveness of Right- and Left-Leaning Group Videos on Social Media}, author = {Ai, Lin and Kathuria, Anika and Panda, Subhadarshi and Sahai, Arushi and Yu, Yuwen and Levitan, Sarah Ita and Hirschberg, Julia}, booktitle = {2021 IEEE international conference on big data (big data)}, pages = {2454--2460}, year = {2021}, organization = {IEEE}, } - Exploring New Methods for Identifying False Information and the Intent Behind It on Social Media: COVID-19 TweetsLin Ai, Run Chen , Ziwei Gong , Julia Guo , Shayan Hooshmand , Zixiaofan Yang , and 1 more authorIn Workshop Proceedings of the 15th International AAAI Conference on Web and Social Media, Jan 2021
The detection of false information is an important task today, because its spread erodes the trust of people with their government and each other and leads to atmospheres of suspicion and growing political divides. Social media, though it has many benefits, such as helping friends stay connected, has contributed to the spread of false information because of its accessible, free, and highly connected nature. Over the past year, false information on social media has played a particularly large role in the perpetuation of false information about COVID-19: where it started, how serious it is, what cures are effective, and how to avoid infection. While there has been much research on how to identify false information, very little work has focused on the intent behind such falsification. In this paper we present our ongoing work on identifying not only false information about COVID-19 but the intent behind its production: is this false information created for purposes of malice or for other purposes? What are the different types of malicious and non-malicious purpose? Can we identify these automatically?
@inproceedings{ai2021exploring, title = {Exploring New Methods for Identifying False Information and the Intent Behind It on Social Media: COVID-19 Tweets}, author = {Ai, Lin and Chen, Run and Gong, Ziwei and Guo, Julia and Hooshmand, Shayan and Yang, Zixiaofan and Hirschberg, Julia}, booktitle = {Workshop Proceedings of the 15th International AAAI Conference on Web and Social Media}, year = {2021}, }


2020
-
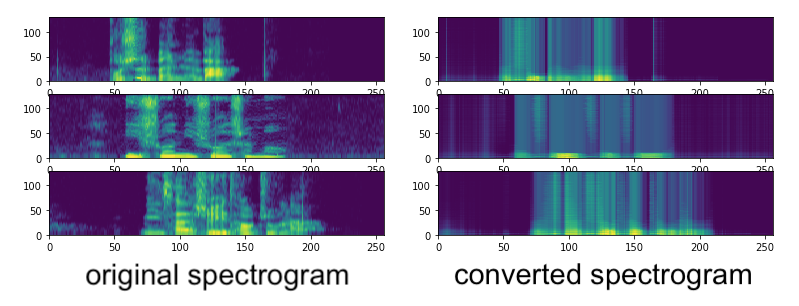 A New Approach to Accent Recognition and Conversion for Mandarin ChineseLin Ai, Shih-Ying Jeng , and Homayoon BeigiarXiv preprint arXiv:2008.03359, Jan 2020
A New Approach to Accent Recognition and Conversion for Mandarin ChineseLin Ai, Shih-Ying Jeng , and Homayoon BeigiarXiv preprint arXiv:2008.03359, Jan 2020Two new approaches to accent classification and conversion are presented and explored, respectively. The first topic is Chinese accent classification/recognition. The second topic is the use of encoder-decoder models for end-to-end Chinese accent conversion, where the classifier in the first topic is used for the training of the accent converter encoder-decoder model. Experiments using different features and model are performed for accent recognition. These features include MFCCs and spectrograms. The classifier models were TDNN and 1D-CNN. On the MAGICDATA dataset with 5 classes of accents, the TDNN classifier trained on MFCC features achieved a test accuracy of 54% and a test F1 score of 0.54 while the 1D-CNN classifier trained on spectrograms achieve a test accuracy of 62% and a test F1 score of 0.62. A prototype of an end-to-end accent converter model is also presented. The converter model comprises of an encoder and a decoder. The encoder model converts an accented input into an accent-neutral form. The decoder model converts an accent-neutral form to an accented form with the specified accent assigned by the input accent label. The converter prototype preserves the tone and foregoes the details in the output audio. An encoder-decoder structure demonstrates the potential of being an effective accent converter. A proposal for future improvements is also presented to address the issue of lost details in the decoder output.
@article{ai2020new, title = {A New Approach to Accent Recognition and Conversion for Mandarin Chinese}, author = {Ai, Lin and Jeng, Shih-Ying and Beigi, Homayoon}, journal = {arXiv preprint arXiv:2008.03359}, year = {2020}, }

2019
- Multimodal Indicators of Humor in VideosZixiaofan Yang , Lin Ai, and Julia HirschbergIn 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Jan 2019
In this paper, we propose a novel approach for generating unsupervised humor labels in videos using time-aligned user comments. We collected 100 videos and found a high agreement between our unsupervised labels and human annotations. We analyzed a set of speech, text and visual features, identifying differences between humorous and non-humorous video segments. We also conducted machine learning classification experiments to predict humor and achieved an F1-score of 0.73.
@inproceedings{yang2019multimodal, title = {Multimodal Indicators of Humor in Videos}, author = {Yang, Zixiaofan and Ai, Lin and Hirschberg, Julia}, booktitle = {2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)}, pages = {538--543}, year = {2019}, organization = {IEEE Computer Society}, }
